
Synthetically created data is gaining great importance and usage in the field of data science. Such kind of data does not arise as a result of events in reality but is fabricated. The various advantages that occur from synthetic data are better privacy, lower costs, and the capability to emulate rare or exact scenarios that could not exist within the actual data set. In this blog, we will go over the idea of synthetic data, its use cases, and the tools used to create synthetic data.
What is Synthetic Data?
Synthetic data is created artificially rather than being collected based on real-life events. The algorithms are used to simulate these data by mimicking the statistical properties and relations found in real-world data. There are several uses of synthetic data, including testing, training a machine learning model, and supplementation of existing datasets.

Examples of synthetic data are:
- Synthetic Images: These are created using computer graphics and generative adversarial networks (GANs).
- Synthetic Text: These are generated using natural language processing (NLP) models.
- Synthetic Tabular Data: These are created using statistical methods and machine learning algorithms to replicate the structure and distribution of real-world tabular data.
Life Cycle of Synthetic Data in Data Science
Here is the pictorial representation of the life cycle of Synthetic Data in Data Science
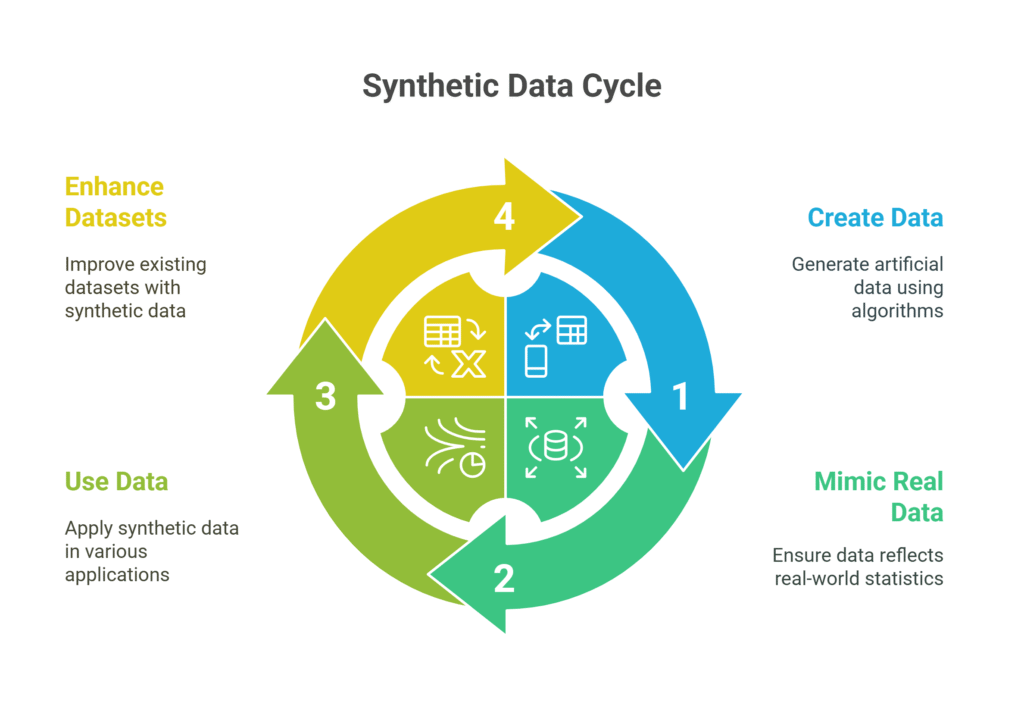
Use Cases of Synthetic Data
1. Privacy Preservation
The most important use case of synthetic data is for privacy preservation. In most sectors, such as health care and finance, the rules of data privacy restrict the use and sharing of sensitive data. Synthetic data lets organizations generate data that looks like real data, yet retains all the statistical properties of the original data, while not exposing any sensitive information. This lets data scientists and researchers work with valuable data without violating any privacy rules.
For example, synthetic patient data may be generated for training machine learning models on predictive analytics, disease diagnosis, and treatment recommendations in the healthcare industry. Synthetic data does not disclose the identity of the patients and is therefore compliant with all regulations, including HIPAA and GDPR.
2. Data Augmentation
Data augmentation is the increase in diversity and volume of available data for training machine learning models. Synthetic data can be used to augment the existing datasets in scenarios where the collection of real-world data proves challenging, time-consuming, or expensive. The augmentation of data helps improve the model’s performance because it provides extra training examples while reducing overfitting.
Example: Artificial images may be created in supplementing datasets with computer vision systems such as object detection, image classification, and face recognition. Through transformations of rotation, scaling, and flipping, new examples may be derived in the training stage.
3. Simulations of Rarer Events
Many times, datasets from the real world are not so good in that they do not contain enough samples of rare events. Synthetic data can be very helpful in generating these rare events to train models for machine learning. This application is particularly prevalent in fraud detection, cybersecurity, and anomaly detection.
Example: Synthetic transaction data would be generated to simulate various fraud scenarios in fraud detection to help train the models on how to identify and stop fraudulent activity, which otherwise would require scarce real-world examples.
4. Testing and Validation
Synthetic data also has the importance of testing and validation of machine learning models and software systems. Controlled environments and test scenarios can be developed by creating organizations to examine the performance as well as the robustness of their models. Synthetic data, for instance, is used for testing edge cases, stress tests, and systems that ensure how models perform well under various conditions.
Example: For the development of autonomous vehicles, synthetic driving data can be created for various kinds of driving scenarios such as different types of weather conditions, roads, and traffic patterns.
Tools Generating Synthetic Data
There are several tools and frameworks for synthetic data generation. The functionalities, ease of use, and types of data produced vary between different tools. Here are some popular tools for synthetic data generation:
1. Synthetic Data Vault (SDV)
Synthetic Data Vault (SDV) is an open-source library developed by the MIT Data to AI Lab. SDV provides tools for generating synthetic tabular data, relational data, and time-series data. It uses machine learning algorithms and probabilistic modeling techniques to learn the distribution and relationships in real-world data and generate realistic synthetic data.
Key Features:
- Support for various data types, including numerical, categorical, and time-series data.
- Ability to model complex relationships and dependencies between data columns.
- Integration with popular data science libraries such as Pandas and Scikit-learn
2. GANs (Generative Adversarial Networks)
GANs are a deep learning set of synthetic data generation models, especially images and text. They include two neural networks, the generator and the discriminator. The generator creates synthetic data while a discriminator reports or identifies its authenticity. The networks both learn in an adversarial manner, where the generator increases its capabilities of creating real data over time.
Key features are as follows:
- Quality generation of high-quality synthetic images, text, or other data.
- Capability of tailoring the architecture and hyperparameters of GAN models.
- High usage in research and industry for data augmentation and artistic applications.
3. CTGAN (Conditional Tabular GAN)
This type of GAN is specially developed for generating synthetic tabular data. This has the special aim to tackle the modeling problem in the case of discrete and mixed-type tabular data. So, it can be applied to many different applications; thus, it is called widely applicable. This method learns conditional distributions for all columns in a dataset, therefore creating highly realistic synthetic data, while retaining all the statistical properties of the source data.
Principal Features:
- Tabular data synthesized with complex dependencies.
- Handling both continuous and categorical data at the same time.
- Open source library with application in data science workflows.
4. Synthpop
Synthpop is an R package that can create synthetic data. It considers the relationships and distributions as in the data it uses through statistical modeling in creating synthetic data. It applies in forms of research social science, in healthcare, among others regarding data privacy and confidentiality.
Key Features:
- User-friendly interface for synthetic data generation.
- Support of various statistical methods and models.
- Well documented with good community support.
5. Faker
Faker is a Python library for creating fake data. It is highly used for test and development environments. Faker creates all sorts of data, such as names, addresses, dates, and many more. Even though it can’t generate extremely realistic synthetic data to be utilized for advanced applications in machine learning, it helps in creating dummy data for testing and development of software.
Key Features:
- Simple and flexible API for generating fake data.
- Multilocal data support and more than one type of data type.
- Very common in software development and testing.
Conclusion
In science, data synthesis offers a myriad of benefits, including privacy preservation, data augmentation, and simulation of rare events. Organizations can only improve their models through machine learning, test and validate better processes, and comply with regulations regarding data privacies by using synthesized data. Since tools and frameworks abound, synthesizing data has proven easier and more practical.
With the rapid advances in data science, this use of synthetic data will go on to drive innovation and unlock new applications. Keeping up with the latest trends and tools will help you take advantage of synthetic data to tackle complex challenges and unlock new opportunities. Whether you are in healthcare, finance, cybersecurity, or in another field, synthetic data can be an invaluable addition to your data science toolkit.

